
We ran a quick fire poll on who was affected by the global IT outage on 19 July and here we take a look at the results, as well as opinions on what could have been done differently; and what we need to be looking at in terms of resilience and business continuity.
Exactly one week ago today (26 July), US cybersecurity giant CrowdStrike infamously released an update to Windows systems that triggered a logic error: systems running Crowdstrike’s Falcon sensor for Windows 7.11 and above in many cases crashed and showed a blue screen of death (BSOD). Crowdstrike has since blamed a bug in its test software, and has promised to take steps to avoid a repeat of an incident that is estimated to have cost Fortune 500 companies over $5bn.

People will likely remember where they were when they became aware of the outage, particularly if you work in IT, were due to fly, were in certain courts, in the middle of a transaction, or any variation of those ‘need to happen now’ situations that didn’t happen. Around 8.5m Microsoft devices were affected, forcing them into a boot loop. Tempers and viewpoints unsurprisingly ran high.
As organisations from banks to law firms to doctor’s surgeries in some cases still continue to pick up the pieces, there are serious questions being asked around what could have been done differently, other than the obvious, which is for Crowdstrike not to release the faulty update in the first place. While Crowdstrike gets the blame fair and square, is there an argument that Microsoft needs better resilience? Will firms be looking critically at their own business continuity and disaster recovery processes and procedures?

A week on and it’s still fairly early days, but there are already some important takeaways and views worth sharing, as we get our heads around how – or more likely if – we could prevent anything like this happening again.
Who was affected?
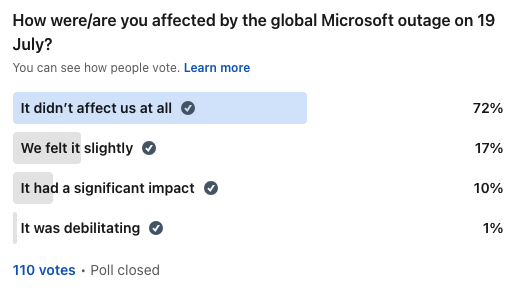
In a snap 24-hour poll on LinkedIn on 19 July, Legal IT Insider tried to gauge how badly the legal sector was affected by the outage – see those results above. The majority weren’t affected at all, according to our informal poll, but for 10% of firms, it had a significant impact. For 1%, it was debilitating.
Heavy Crowdstrike shops were hit hardest but those firms we spoke to were also largely cloud-based. In the US, Steptoe & Johnson’s chief information officer Isidore Okoro told Legal IT Insider that the firm, where Crowdstrike is on every machine and server, is 100% cloud, commenting: “So the fix was much easier for us to implement than if we had physical servers on prem.”
He added: “Very few SaaS services were affected. So iManage Cloud, our Zoom phone system, Microsoft 365, etc. were still up and functioning fine. In fact, that was what saved our bacon. We are heavily invested in SaaS based services.”
In the UK, Sackers, which uses both Crowdstrike and Aderant Sierra, which was impacted, head of IT Danny O’Connor had a similar story, commenting: “I’m glad we’re mostly SaaS, so this has been someone else’s problem to fix.”
Reflecting the views of many, O’Connor said: “How on earth did this update get out of testing? It should go through different bands before it reaches production, so how did it come to be released?”
More regulation?
This question from O’Connor is the million, or more like billion-dollar question, and the chaos and loss of business on Friday and beyond has led to calls for more regulation of big tech companies.
Professor Ciaran Martin, the former chief executive of the National Cyber Security Centre (NCSC), who is speaking at ILTACON Europe in November, told Sky News: “Until governments and the industry get together and work out how to design out some of these flaws, I’m afraid we are likely to see more of these again.”
Not all agree, to say the least. In a delightfully bombastic post on 21 July, digital media attorney and journalist Greg Bufithis said: ” I had to cringe by this tweet from FTC Chair Lina Khan who tried to make the current CrowdStrike/Microsoft global IT melt-down situation a crisis because of “big tech” and “consolidation”…Pardon my French, Lina, but how in fuck is it that you don’t understand systems, or their inherent complexity? Well, if you give someone a hammer, everything looks like a nail.”
Bufithis added: “Any of my regular readers know that I’m a little skeptical (ok, completely skeptical and cynical) of government regulators (including the DOJ, the FTC, the SEC, etc etc) being able to control and rein in Big Tech, and more importantly, bring about change that it timely, impactful, and meaningful in the long run. This lack of understanding of the complexity of our model technology-reliant, digital-first world is why all of these regulators need to rethink regulation and regulatory frameworks.”
Let us also not forget that it was EU regulation that prevented Microsoft from keeping third parties out of the kernel space: concerned over Microsoft’s market dominance, the European Commission in 2009 secured a deal with Microsoft where it would give makers of security software the same level of access to Windows that Microsoft gets. Apple, on the other hand, in 2020 stopped giving developers access to its MacOS operating system, and consequently was not affected by the Crowdstrike update on Friday.
Business continuity and resilience
Like it or not, and whether we can agree on the solution or not, there is no doubt that the outage has (again) brought to the fore the business continuity risk of a global dependence on a small number of businesses.
The need to understand your supply chain was brought into sharp relief by global cyberattacks like Solar Winds but with the recent outage, experts are advising that organisations now need to identify dependencies and vulnerabilities in terms of resilience against disruptive events (so, not unlike a cyberattack.)
Much of the expert advice being dished out is well trodden ground – proactively identify dependencies and vulnerabilities; don’t put your eggs in one basket; work out where your single points of failure are; back up, and actively and aggressively stress test.
But the outage has many IT heads shaken and thinking about any areas where we can do things differently. One question being raised is whether we need to rethink automatic updates. Cybersecurity member group ISC2 has a post worth reading on some of the lessons learned, and says: “Depending on the organization and the operating scenario, it may or may not be worth the risk of allowing systems to acquire and deploy their own updates automatically. That means either pulling those updates into an internal testing environment, or at least have direct automated updates disabled in favor of polling a centrally managed update server as part of a managed enterprise patch deployment solution. The latter can at least allow time to be built into the deployment process, to lower the risk of defective updates being rolled out to critical systems and users before issues are discovered.” This feels like a backwards step resource wise for cloud-based firms that are redeploying and retraining their IT staff.
Microsoft, to blame, or not to blame?
One question we have posed on LinkedIn, which has caused significant debate, is whether Microsoft itself should not have been more resilient.
While Legal IT Insider has seemingly been in the minority in arguing this point, J.J. Guy, CEO of Sevco Security made an interesting point on LinkedIn: “Yes, CrowdStrike pushed a kernel-level update that causes widespread blue screens. Yes, that should have been caught during quality assurance (QA)… This is a high-impact incident not because there was a blue screen, but because it causes repeated blue screens on reboot and [appears as of right now] to require manual, command-line intervention on each box to remediate (and even harder if BitLocker is enabled).
“That is the result of poor resiliency in the Microsoft Windows operating system. Any software causing repeated failures on boot should not be automatically reloaded. We’ve got to stop crucifying CrowdStrike for one bug, when it is the OS’s behavior that is causing the repeated, systemic failures.”
As usual, where technology and in particular cybersecurity is involved, the issue is complicated.
Ben Swindale, CTO of Grant Thornton in Australia, told us on LinkedIn: “If Microsoft blocked alternate suppliers and forced their solution (Defender) as the only option or the default option, I’m sure the antitrust regulators would be back on their case. This is a Crowdstrike issue, I think it’s a stretch to put the blame on others.”
Daniel Pollick, who is an independent IT consultant and Lawtech mentor among other things, was CIO of DLA Piper when it got hit by the NotPetya malware attack, added: “Yes it’s dopey architecture but imagine instead of a bad update causing a BSOD a bad actor had penetrated Crowdstrike’s updater and done far worse? That’s getting close to very bad. It’s basically what happened with NotPetya (I have the scars!) but a thousand timed worse.”
Interestingly, better education and implementation could have played a part in minimising the impact, and Mike Walker, chief innovation and technology officer at Peppermint, said: “There is a recovery mode in the boot process but only if implemented, which would have noted a bad driver and auto disabled it…hence the reboot many times suggestions. The issue here is it needs to be configured and deployed properly.”
He added: “There is a Windows Recovery Environment and it is possible to remote manage as well so architecturally the issue is education and implementation.”
Conclusion
In an interconnected world, cybersecurity experts are predicting that global tech outages such as this one are inevitable. There are a few conclusions and takeaways, and we’re sure you can add to this.
- Review your supply chain regularly
- Revisit your business continuity and disaster recovery plans
- Review your resourcing arrangements (people fixed this problem)
- Take on the wider lessons from this disaster (see Mike Walker’s observations above, for example)
- Be agile to change
Helpfully or unhelpfully, the outage is a reminder that even the largest tech vendors can completely screw up.






